Given a restoration model pre-trained on synthetic datasets in a supervised fashion, it can produce high-quality restoration on low-quality images that are aligned with the degradation distribution used in training (a). However, it often fails on inputs of out-of-distribution degradations (b). We propose an unsupervised pipeline to adapt a pre-trained model to unpaired degraded images of the target degradation with a much smaller data size. This addresses the domain gap in degradation types without paired ground-truth images or the knowledge of the target data's degradation type (c).
Video
Abstract
Blind face restoration methods have shown remarkable performance, particularly when trained on large-scale synthetic datasets with supervised learning. These datasets are often generated by simulating low-quality face images with a handcrafted image degradation pipeline. The models trained on such synthetic degradations, however, cannot deal with inputs of unseen degradations. In this paper, we address this issue by using only a set of input images, with unknown degradations and without ground truth targets, to fine-tune a restoration model that learns to map them to clean and contextually consistent outputs. We utilize a pre-trained diffusion model as a generative prior through which we generate high quality images from the natural image distribution while maintaining the input image content through consistency constraints. These generated images are then used as pseudo targets to fine-tune a pre-trained restoration model. Unlike many recent approaches that employ diffusion models at test time, we only do so during training and thus maintain an efficient inference-time performance. Extensive experiments show that the proposed approach can consistently improve the perceptual quality of pre-trained blind face restoration models while maintaining great consistency with the input contents. Our best model also achieves the state-of-the-art results on both synthetic and real-world datasets.
Method
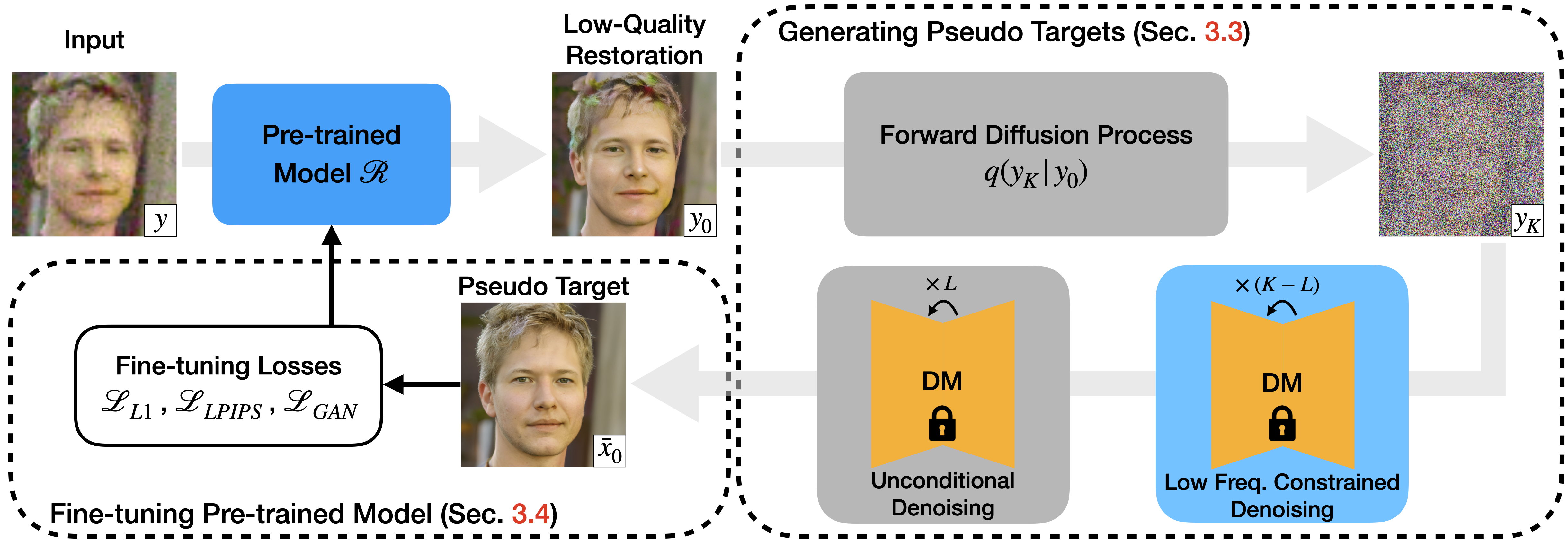
Given a pre-trained restoration model that produces low-quality restoration outputs (severe artifacts on hair and over-smoothed skin) on samples with unknown and out-of-distribution degradations, we generate pseudo targets using a pre-trained unconditional diffusion model with a combination of low frequency content constrained denoising and unconditional denoising. The generated clean images can be used as pseudo GT to fine-tune the pre-trained restoration model without the need for real GT images.
Improvements upon Pre-trained Models
SwinIR
CodeFormer
















Interactive comparison between pre-trained (left) and our fine-tuned (right) models for SwinIR and CodeFormer.
